Transfer Learning
Transfer learning is a machine learning method where a model developed for a task is reused as the starting point for a model on a second task.
In transfer learning, we leverage prior knowledge from one domain into a different domain. The way transfer learning is done is by deleting the last output layer and creating a new set neural network layers for the new problem. Then these layers are trained using the new data set.
For example, let’s say you have an AI model to recognize cats, now we can use that knowledge to recognize elephants. The model for recognizing cats is created by training the model with pictures of cats (plenty on the internet). Once the model is trained to recognize cats with high accuracy, then the last layer of the neural network will be replaced with additional layers and those layers will be trained using pictures of elephants to recognize elephants. This is done so that a lot of the low-level features like detecting edges, curves, etc. could be learned from the large dataset (in this case Cats) and the newer model will be trained to recognize specific elements (elephants specific features) with fewer data as shown in the below figure.
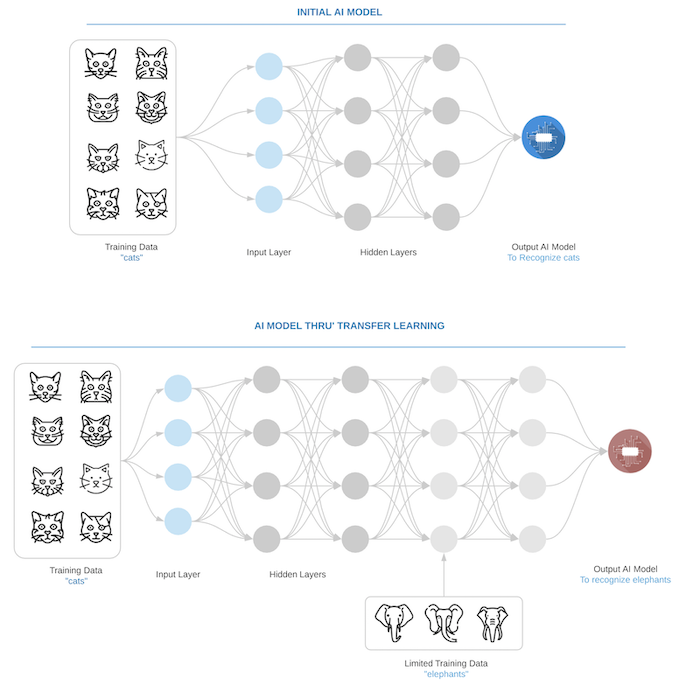
Most of the success today in achieving high accuracy in AI models has been driven by extensive supervised learning which relies on large amounts of labeled datasets. For simple use cases, large amounts of labeled public data is available through various online sources (Ex: ImageNet, WordNet, etc.) but if you are building a model for a specific domain solution, large amounts of labeled data is hard to obtain or data will need to be cleaned and labeled manually for building the model. Transfer learning enables you to develop fairly accurate models using comparatively little data. This is very useful at enterprises that might not have a lot of clean labeled data.
Therefore on some problems where you may not have very much data, transfer learning will enable you to develop skillful models that you simply could not develop in the absence of transfer learning.
