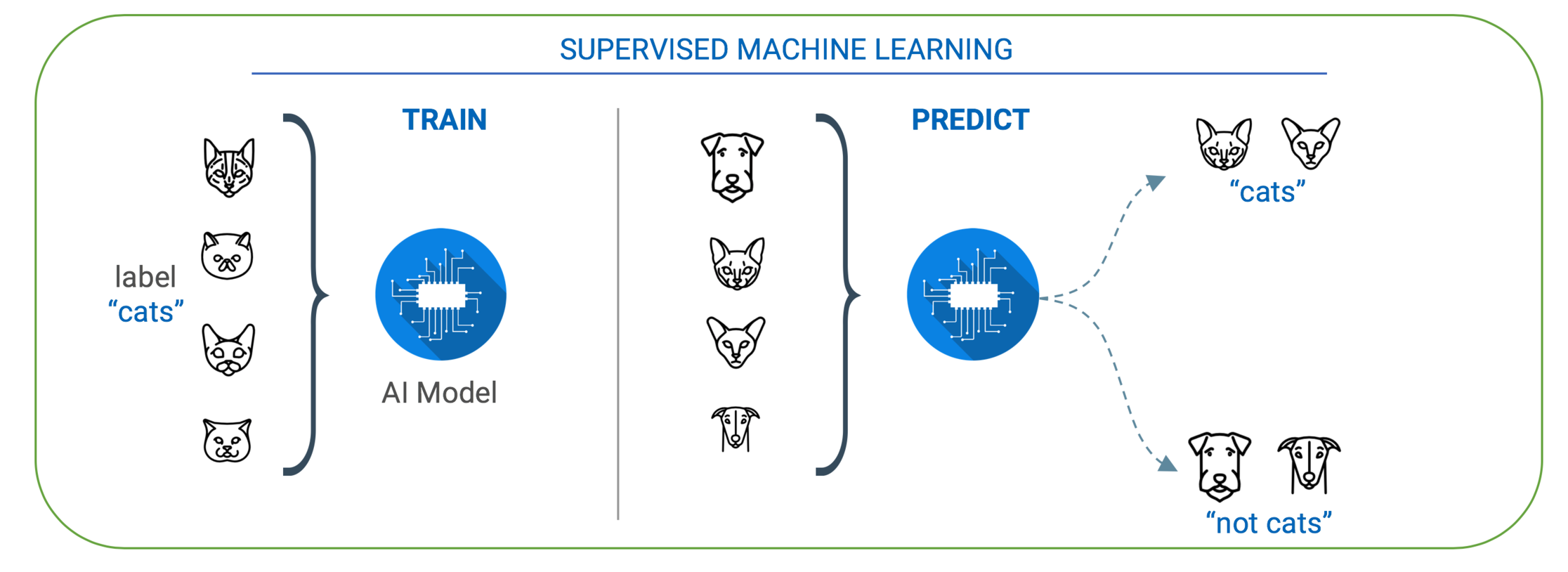
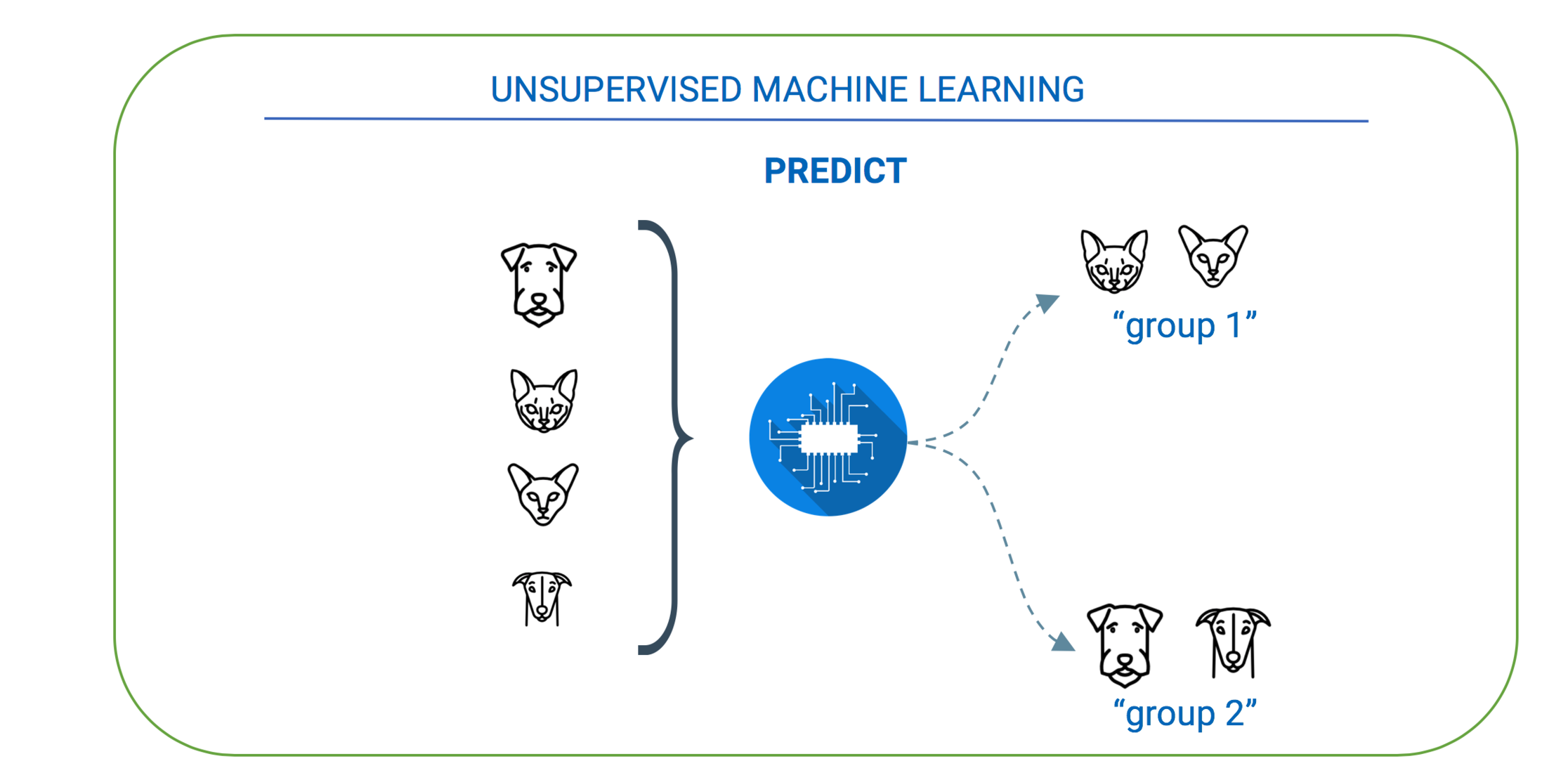
What is Deep Learning?
Deep Learning is a subset of machine learning that allows machines to do tasks that typically require human like intelligence. The inspiration for deep learning comes from neuroscience, if you look at the architecture of Deep Learning Neural Networks, they are connected in a fundamental way that mirrors the brain. Deep-learning networks are distinguished from the more commonplace neural networks by their depth; that is, the number of node layers through which data passes in a multistep process.
Earlier versions of neural networks were shallow, composed of one input and one output layer, and at most one hidden layer in between. More than three layers (including input and output) qualifies as “deep” learning. So deep as strictly defined means more than one hidden layer.
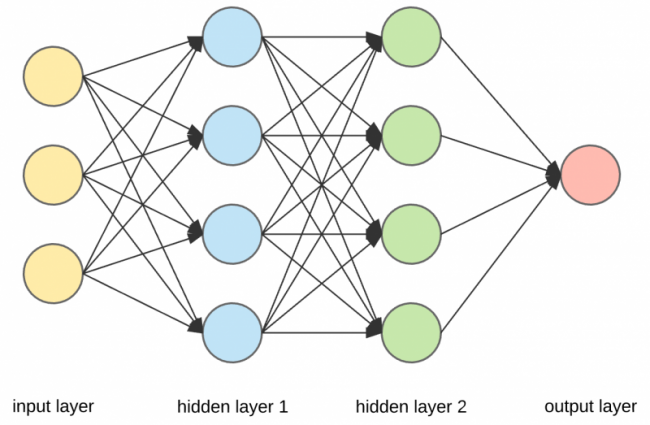
Deep learning Neural network
In deep-learning networks, each layer of nodes trains on a distinct set of features based on the previous layer’s output. The further you advance into the neural net, the more complex the features your nodes can recognize, since they aggregate and recombine features from the previous layer.
Let’s take a simple example of recognizing hand written numbers from 1 – 10. If 10 people wrote the numbers, the numbers will look very different from each person. For a human brain, it is fairly easy to identify these numbers. For a traditional machine it is impossible to detect and hence Neural Networks are used to mimic the way, neurons in the brain interact. These multiple hidden layers allow a computer to determine the nature of a handwritten digit by providing a way for the neural network to build a rough hierarchy of different features that make up the handwritten digit.
For instance, if the input is an array of values representing the individual pixels in the image of the handwritten figure, the next layer might combine these pixels into lines and shapes, the next layer combines those shapes into distinct features like the loops in an 8 or upper triangle in a 4, and so on. By building a picture of these features, neural networks can determine with a very high level of accuracy the number that corresponds to a handwritten digit. Additionally, the model will learn which links between neurons are critical in making successful predictions during training. Over the course of several training cycles, and with the help of occasional manual tuning, the network will continue to learn and generate better predictions until it reaches desired accuracy.
Thus, Deep learning allows machines to solve complex problems even when using a data set that is very diverse, unstructured and inter-connected. Deep learning networks excel at dealing with vast amount of disparate data. In fact, the larger the amount of data the more efficient Deep learning becomes and the more deep learning algorithms learn, the better they perform.
Few additional links on this topic:
MIT Technology Review: https://www.technologyreview.com/s/513696/deep-learning/
Cambridge Univerisity paper: https://bit.ly/2Fbbrlr