
Text Classification: Binary to Multi-label Multi-class classification
Unstructured data in the form of text is everywhere: emails, web pages, social media, survey responses, domain data and more. While textual data is very enriching, it is very complex to gain insights easily and classifying text manually can be hard and time-consuming. For businesses to make intelligent data-driven decisions, understanding the insights in the text in a fast and reliable way is essential. Artificial Intelligence makes that possible with Natural Language Processing (NLP) and text classification. The capability to automatically classify text into one or more categories have seen tremendous improvements in recent years. Gone are the days of manually tagging textual data which can be laborious, time-consuming, inconsistent and expensive.
So let’s look at a few types of text classification in AI.
Binary classification: As the name suggests is the process of assigning a single boolean label to textual data. Example: Reviewing an email and classifying it as good or spam.
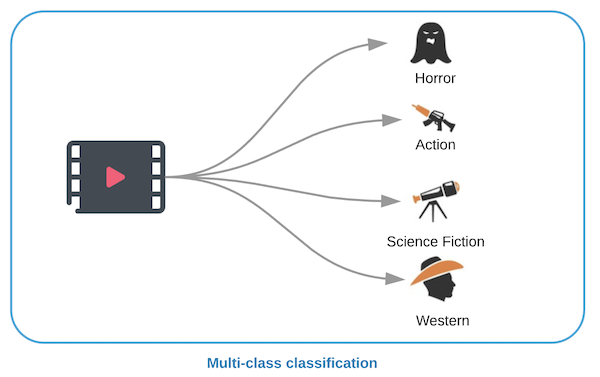
Multi-class classification: Multi-class classification involves the process of reviewing textual data and assigning one (single label) or more (multi) labels to the textual data. The complexity of the problem increases as the number of classes increase. Lets take an example of assigning genres to movies. Each movie is assigned one or more genres from a list of movie genres (Drama, Action, Comedy, Horror, etc.). This is a Multi-class classification problem with a manageable set of labels.
Now imagine a classification problem where a specific item will need to be classified across a very large category set (10,000+ categories). The problem becomes exponentially difficult. Here is where eXtreme Multi-Label Text Classification with BERT (X-BERT) comes into play. If you want to learn more about Google’s NLP framework BERT, click here.
X-BERT aims to tag each input text with the most relevant labels from an extremely large label set.
Here are a few examples of multi-class classification: Classifying a product in retail to product categories. There are hundreds of thousands of product categories (https://www.researchandmarkets.com/categories) and classifying a single product to one of category based on the product description constitutes a multi-label (specific product category) multi-class ((broader product category) example.
Displaying sponsored content based on user search queries. There are thousands of combinations of ways, users can type in a search query and in order to classify user inputs to display a specific ad under sponsored ads is another extremely large classification example.
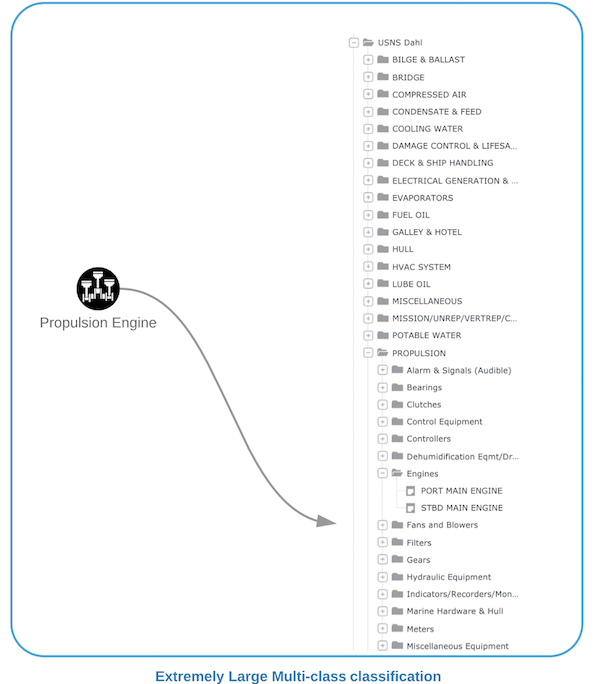
In the work we do for the US Navy, we tackle a similar problem of identifying a single equipment name & id from a list of equipment names across ships. The need is to find the right equipment from a list of 50,000+ items with more than 90% accuracy. We utilized X-BERT model connected to additional dense layer and softmax layer to conduct fine-tuning training to identify the equipment. This combined with the subject matter expert validation and verification helped train the machine to get better over time in identifying the equipment.
As shown in the examples above, with the right methodology and data training, unstructured text can be categorized automatically using AI NLP technology. Employing AI-based auto-classification will make classification more effective and efficient.