
How do Machines Learn?
A good definition by TechEmergence states that “machine learning is the science of getting computers to learn and act like humans do, and improve their learning over time in autonomous fashion, by feeding them data and information in the form of observations and real-world interactions.”
From the definition it is fairly apparent that all forms of machine learning (ML) rely on the availability of data, not just some data but large volumes of data. Therefore, in order to take advantage of ML, access to large sets of well-organized data is critical. As far as machine learning goes, there are several approaches; from a simple decision tree to multilayered neural networks, all depending on the task and amount and type of available data.
There is no one-size-fits-all solution when it comes to a machine learning algorithm. Most times, the best solution is derived when working on real applications with real data because every organization’s data is unique. Solutions are derived by working with domain experts and creating custom neural networks.
There are a few methods to teach the machine with data: supervised learning, unsupervised learning and semi-supervised learning.
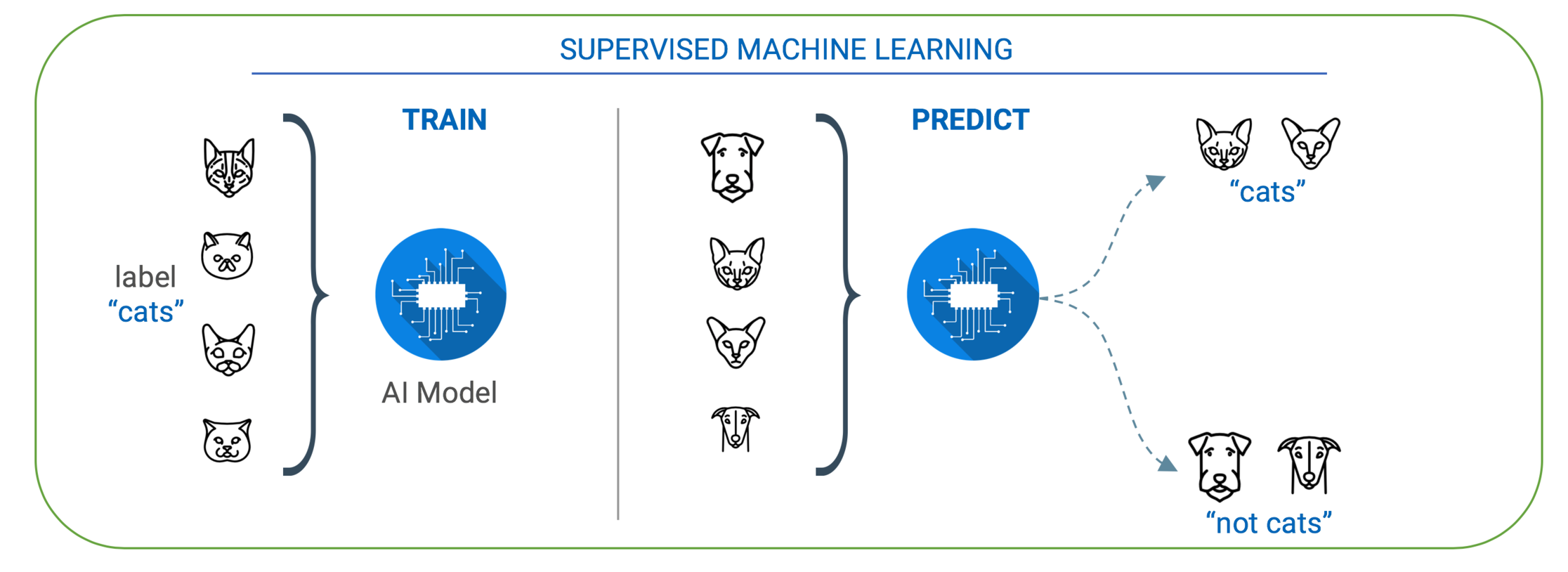
Supervised Learning: In supervised ML, the artificial intelligence (AI) model is given data that is labeled in an organized fashion. For example, one might provide pictures of cat with the labels. Once enough structured and labeled data is provided, the AI model built can recognize and respond to patterns in data without explicit instructions. The output and the accuracy of supervised learning algorithms are easy to measure making supervised learning the most common method of machine learning today.
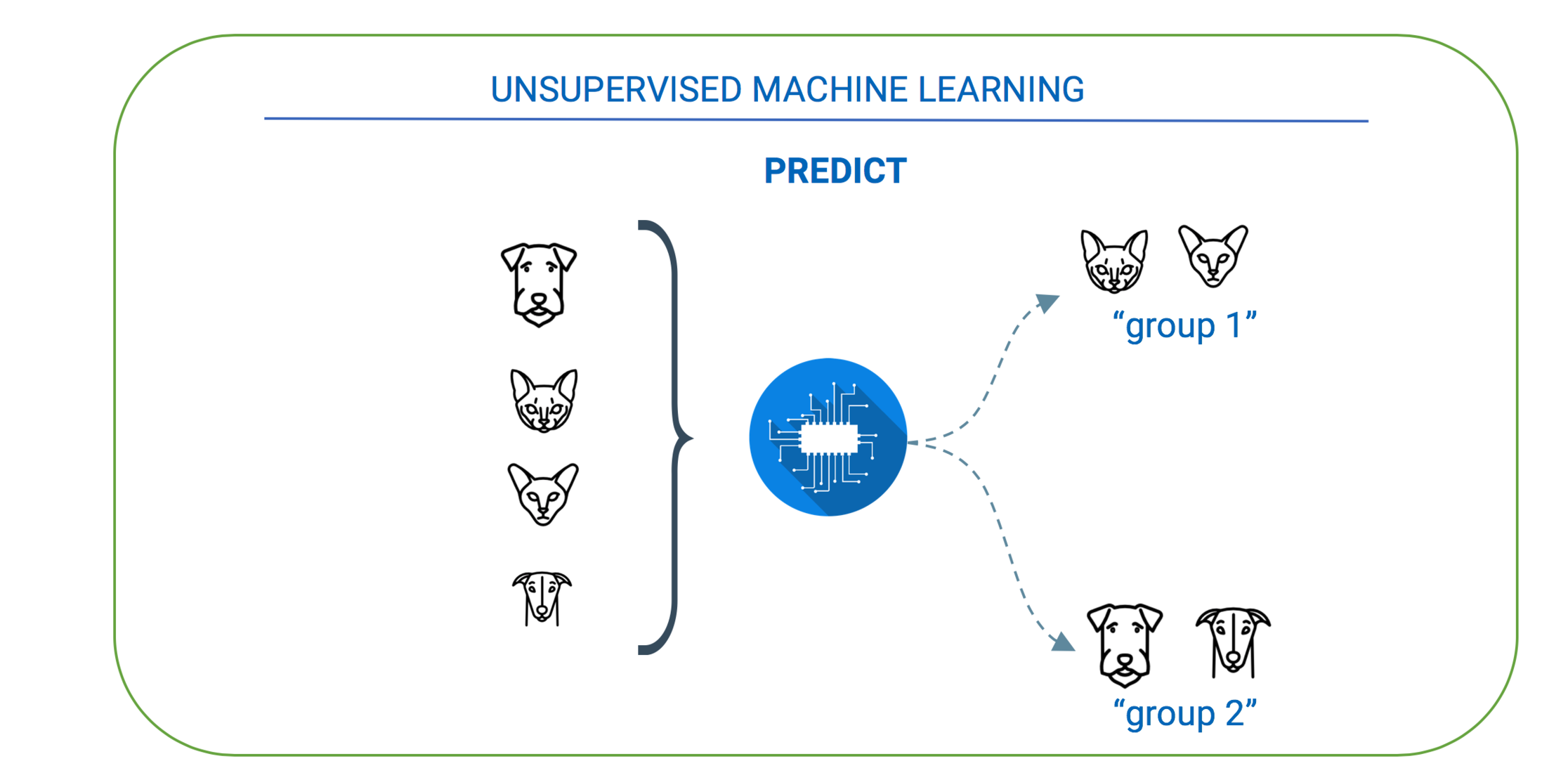
Unsupervised learning: You guessed it, it’s the opposite of supervised learning. Here the AI model is given data that is not labeled in an organized fashion. For example, one might provide pictures of animals (cats, dogs, etc.) without any labels. This method is used to identify underlying patterns or hidden structures from unlabeled data. The expectation is not to derive the right output but to explore datasets and draw inferences. This is rarely used today as the implications of unsupervised learning are unknown.
Semi-supervised learning: This method falls somewhere between supervised and unsupervised data. In this scenario, the model is given a small amount of labeled data and a much larger pool of unlabeled data. Semi-supervised learning combines the best of both worlds by having improved accuracy associated with supervised ML and makes use of unlabeled data. Often, the process of labeling massive amounts of data for supervised learning is time consuming and expensive. This process actually tends to improve the accuracy of the final model while reducing time and cost.
So what method should be used? Well, it depends. The structure and volume of data should inform the method and the approach that needs to be taken. Hence, there is not a one-size-fits-all solution when it comes to machine learning.
Next we will talk about deep learning, a powerful machine learning technique.

