
Google’s BERT takes NLP to much higher accuracy
As a follow up to my earlier LinkedIn Post of Google’s BERT model on NLP, I am writing this to explain further about BERT and the results of our experiment.
In a recent blog post, Google announced they have open-sourced BERT, their state-of-the-art training technique for natural language processing (NLP) applications. The paper released (https://arxiv.org/abs/1810.04805) along with the blog is receiving accolades from across the machine learning community. This is because BERT broke several records for how well models can handle language-based tasks and more accurately NLP tasks.
Here are a few highlights that make BERT unique and powerful:
- BERT stands for Bidirectional Encoder Representations from Transformers. As the name suggests, it uses Bidirectional encoder that allows it to access context from both past and future directions, and unsupervised, meaning it can ingest data that’s neither classified nor labeled. This is unique because previous models looked at a text sequence either from left to right or combined left-to-right and right-to-left training. This method is opposed to conventional NLP models such as word2vec and GloVe, which generate a single, context-free word embedding (a mathematical representation of a word) for each word in their vocabularies.
- BERT uses Google Transformer, an open source neural network architecture based on a self-attention mechanism that’s optimized for NLP. The transformer method has been gaining popularity due to its training efficiency and superior performance in capturing long-distance dependencies compared to a recurrent neural network (RNN) architecture. The transformer uses attention (https://bit.ly/2AzmocB) to boost the speed with which these models can be trained.As opposed to directional models, which read the text input sequentially (left-to-right or right-to-left), the Transformer encoder reads the entire sequence of words at once. This characteristic allows the model to learn the context of a word based on all of its surroundings (left and right of the word).
- In the pre-training process, researchers used a masking approach to prevent words that’s being predicted to indirectly “see itself” in a multi-layer model. A certain percentage (10-15%) of the input tokens were masked to train the deep bidirectional representation. This method is referred to as a Masked Language Model (MLM).
- BERT builds upon recent work in pre-training contextual representations — including Semi-supervised Sequence Learning, Generative Pre-Training, ELMo, and ULMFit. BERT is pre-trained on 40 epochs over a 3.3 billion word corpus, including BooksCorpus (800 million words) and English Wikipedia (2.5 billion words). BERT has 24 Transformer blocks, 1024 hidden layers, and 340M parameters. The model runs on cloud TPUs (https://cloud.google.com/tpu/docs/tpus) for training which enables quick experimentation, debug and to tweak the model
- It enables developers to train a “state-of-the-art” NLP model in 30 minutes on a single Cloud TPU (tensor processing unit, Google’s cloud-hosted accelerator hardware) or a few hours on a single graphics processing unit.
These are just a few highlights on what makes BERT the best NLP model so far.
Our Experiment:
To evaluate the performance of BERT, we compared BERT to IBM Watson based NER. The test was performed against the same set of annotated large unstructured documents. The model created using BERT and IBM Watson was applied to the annotated large unstructured documents. Below table shows the results we achieved:
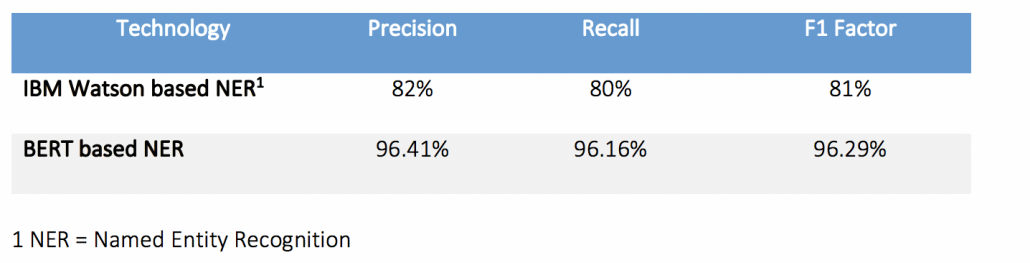
Based on our comparison and what we have seen so far, it is fairly clear that BERT is a breakthrough and a milestone in the use of Machine Learning for Natural Language Processing.

