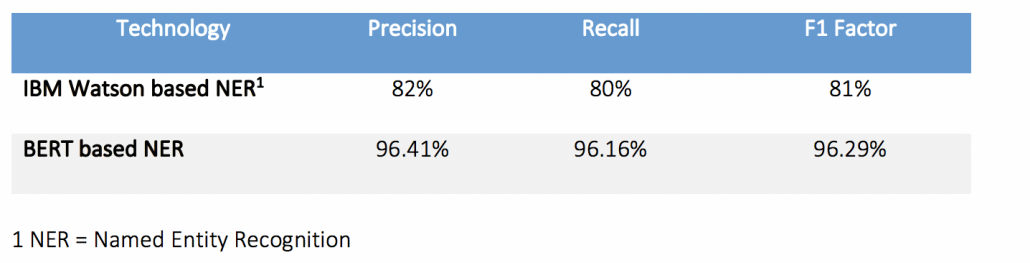
NLS: Natural Language Search is a search using everyday spoken language, such as English. Using this type of search, you can ask a database a question or type in a descriptive sentence that describes your question.
Though asking questions in a more natural way (ex: What is the population of England as of 2018? Or who was the 44th president of America?) has only recently come into its own in the field, natural language search engines have been around almost as long as web search.
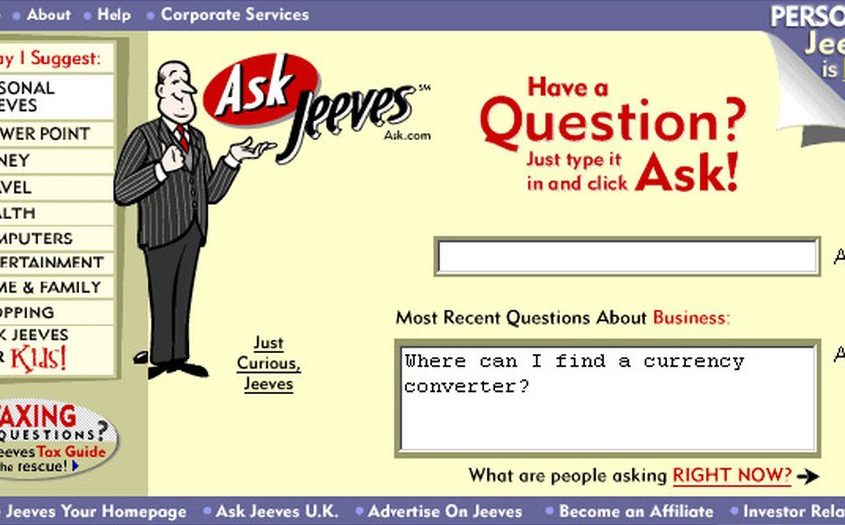
Remember Ask Jeeves? The 1996 search engine encouraged its users to phrase their search queries in the form of a question, to be “answered” by a virtual suited butler. Ask Jeeves was actually ahead of its time in this regard when other search engines like Google and Yahoo were having greater success with keyword-based search. In 2010, Ask Jeeves finally bowed to the pressure from its competition and outsourced its search technology. Ironically, had Ask Jeeves been founded about fifteen years later, it most likely would have been at the cutting edge of natural language search, ahead of the very search engines that squeezed it out.
Today the advent of smart speakers and mobile phones has brought voice-based search and conversational search to the forefront. Advances in NLP (Natural Language Processing) technology has made this possible not just for search giants like Google and Microsoft but also for enterprises to search their internal knowledge base and domain data utilizing artificial intelligence (AI).
Anyone who has used an enterprise application will be familiar with multiple criteria search boxes (like below).
These searches are cumbersome and perform search on structured data stored in the database. As more and more data are now being stored in NOSQL databases and in unstructured text across documents and folders, the need for search across these data sources becomes essential. A simple Boolean search (a simple search for keywords) does not provide the extensive search capabilities necessary to review complex relationships between topics, issues, new terms, and languages. It’s 2019 – searches need to, and can, go beyond simple keyword matching.
An effective search will need to include indexed data that is extracted from a knowledge base using AI technologies like NER (Named Entity Recognition), OpenIE (Information Extraction), key phrase extraction, Text classification, STS (Semantic Text Similarity) and Text Clustering. The data extracted from the above processes will need to be classified, indexed and stored using a multi-label classification technology. This classification methodology will populate the database with knowledge, links, and relations between all data sources. Data, along with structured data stored through transactional operations, will then be used to train the AI models in understanding entities, relations, and common phrases. And that’s where natural language search comes in. NLS provides an efficient way to search data stored in structured or unstructured formats (like scanned pdf documents etc.) thereby providing a comprehensive search across all data.
You can think about it like this: Take a query from an engineer like “Show me Oil Leaks on Main Engine for TAO class in the last 2 years.” The ships that belong to a specific class are stored in a structured database where specific oil leak failures are in repair text as unstructured information. Using AI models to extract this information and index it will provide the ability to answer this query with much more accuracy and greater speed – digging through documents is not going to be the best use of your time. In this case, the query will be analyzed by the model to identify entities that fit the query and dynamically build a solution query to retrieve information from the appropriate data store.
Artificial intelligence has enabled the possibility of implementing NLS within enterprises. This will increase the efficiency and effectiveness of search while reducing the time to perform searches.