Knowledge Integration in AI
So let’s think about how humans learn, we humans are very good at continuously enriching and refining our knowledge and skills by seamlessly combining existing knowledge with new experiences. We exhibit a wide spectrum of learning abilities in various fields. We can be lawyers during the day and go play tennis or go for a run in the evening and make dinner at night. We are fairly adept at doing multiple tasks. When you think about AI systems, that is usually not the case. AI systems are very good at doing a specific task through machine learning alternatively called Narrow Intelligence.
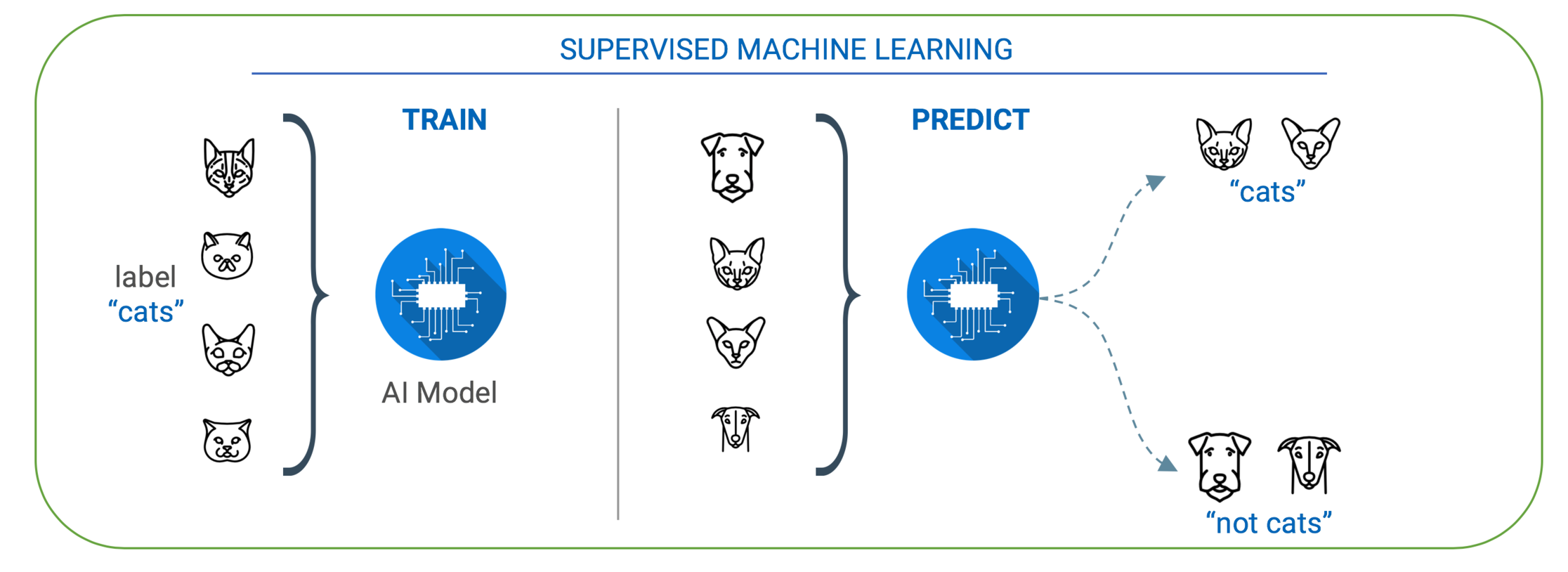
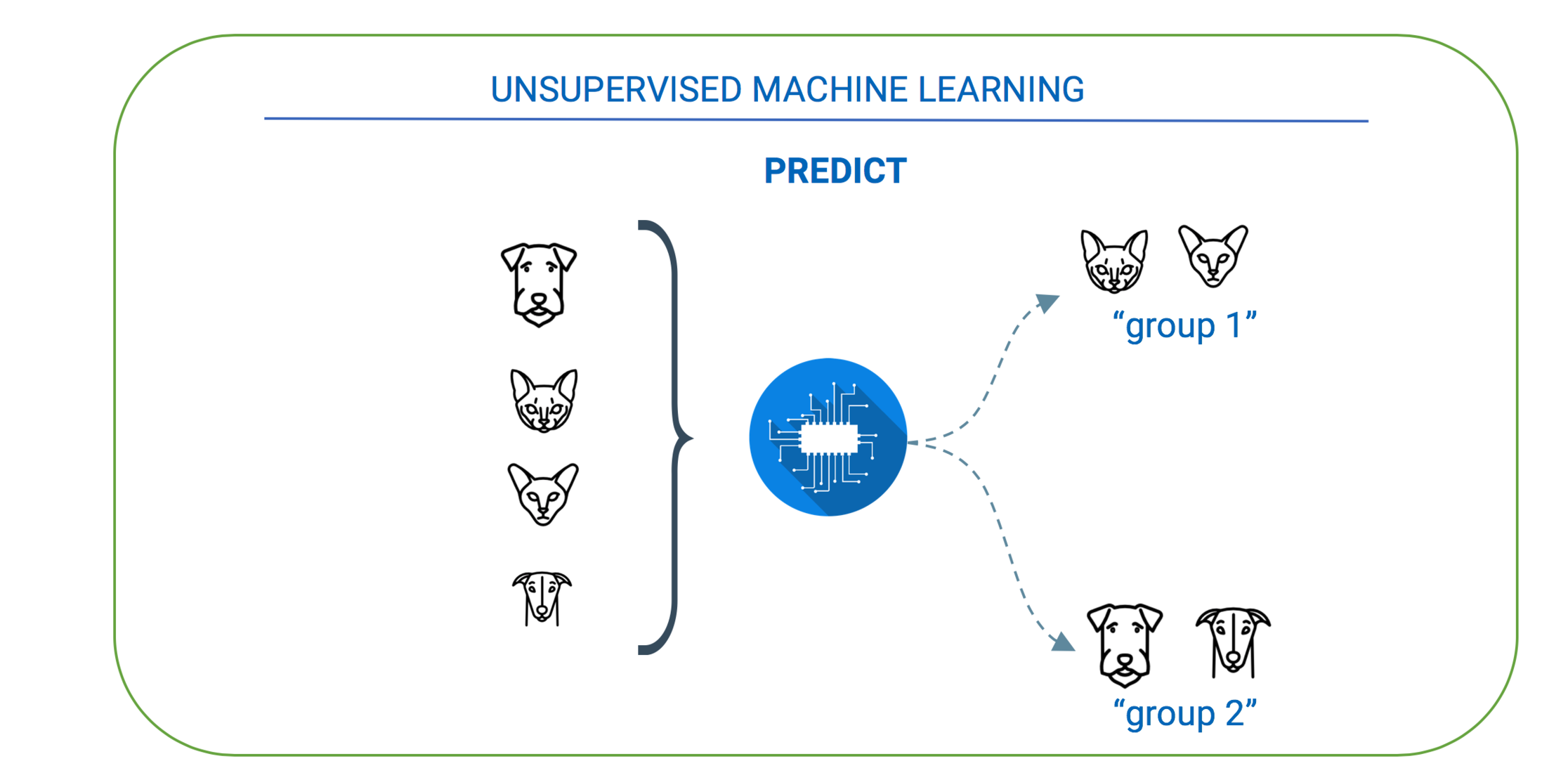
Despite recent breakthroughs and advances, machine learning has a number of shortcomings when it comes to obtaining knowledge in various fields and in developing methods to identify how new and prior knowledge interact to gain more insights. Knowledge integration is the process of synthesizing multiple knowledge representations into a common model. It represents the process of how new information and existing information interact, what effects will the new information will have on existing knowledge and if existing information needs to be modified to accommodate new information.
Why is this concept important? It is important for building a better machine learning model for enterprise knowledge insights. Not all knowledge will be readily available or can be fed into the machine learning model at once. Substantial knowledge bases are developed incrementally and a growing body of knowledge will need to be added separately. By identifying subtle conflicts and gaps in knowledge, KI facilitates better learning models. Large firms like Google are using a combination of Symbolic AI, Deep learning and Supervised learning to create better knowledge understanding and knowledge reasoning.
If you are an organization looking to extract valuable information and identify patterns within your data to create efficiency, these concepts are critical and I highly recommend doing further research around these to achieving success.