
Bring clarity to unstructured data using Natural Language Processing (NLP) – Part 2
Natural language processing (NLP) is a branch of artificial intelligence that helps computers understand, interpret and manipulate human language, in particular how to program computers to process and analyze large amounts of natural language data.
This is series 2 of the introduction to key capabilities of NLP technologies. Here is the link to Series 1 of this article. With recent advances in Artificial intelligence technologies, computers have become very adept at reading, understanding, and interpreting human language. Here a few additional NLP capabilities that have made that possible.
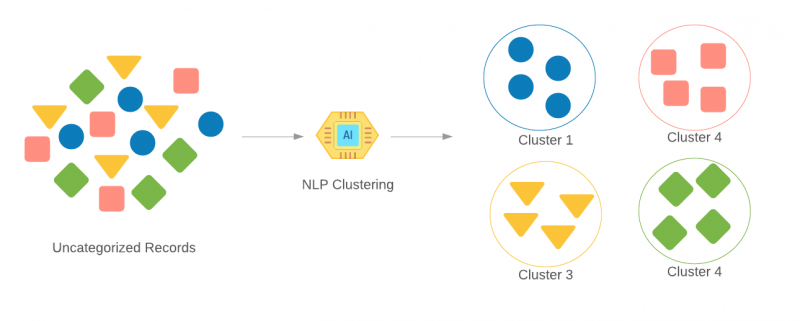
Text Clustering:
Clustering in general refers to the grouping of similar data together. Text clustering is a technique used to group text or documents based on similarities in content. It can be used to group similar documents (such as news articles, tweets, and social media posts), analyze them, and discover important but hidden subjects. Text classification as we discussed before also puts objects in a group, but the major difference between clustering and classification is that classification is a supervised method whereas clustering in an unsupervised method. All objects/data within clustering are new and no the resultant groups are unknown. This method is heavily used to identify key topics, patterns in large data sets as the first step to classification.
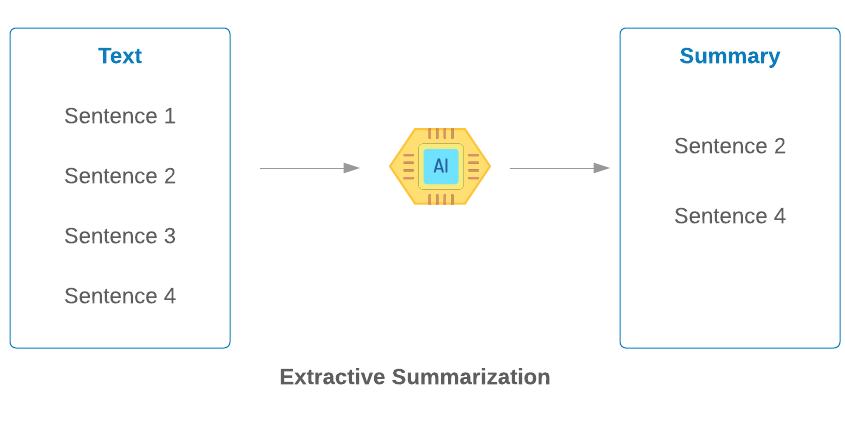
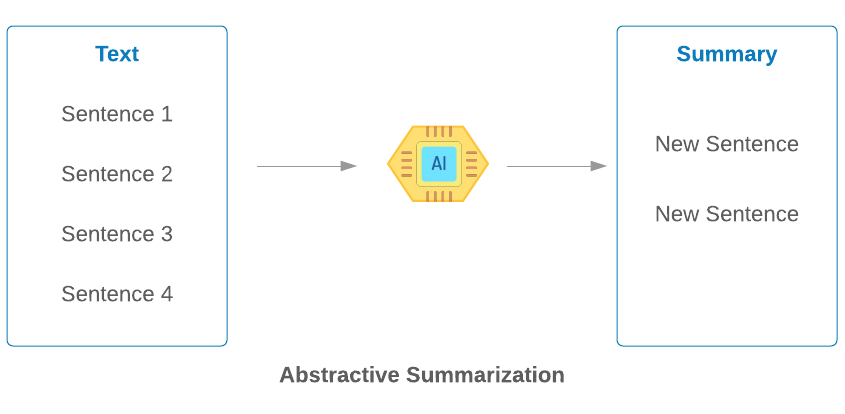
Text Summarization:
Text Summarization refers to the technique of producing a concise summary of long pieces of text while preserving key information, content and overall meaning. There are many reasons and uses for a summary of a larger document. One example that might come readily to mind is to create a concise summary of a long news article, but there are many more cases of text summaries that we may come across every day. There are two different approaches that are used for text summarization: Extractive Summarization, Abstractive Summarization. Extractive Summarization identifies the important sentences or phrases from the original text and extracts only those from the text. Abstractive Summarization generates new sentences from the original text.
Relation Extraction:
Relationship extraction refers to the technique of extracting semantic relationships from a text. Relationship Extraction products attributes and relations for entities in a sentence. For example: given the sentence “John was born in Fairfax, Virginia” a relation classifier aims at predicting the relation of “bornInCity”. Relation Extraction is the key component for building relation knowledge graphs, and it is of crucial significance to natural language processing applications such as structured search, sentiment analysis, question answering, and summarization.
These techniques combined with techniques discussed in series 1, can provide tools to create value from the deluge of unstructured data found within government agencies and other organizations. There is much to be learned from the potential of AI and, in particular, its ability to analyze masses of unstructured data
Want to learn more about AI concepts? Click here to see our Insights series






